
 繁体
繁体
第十一章数据海洋和爬虫(2/2)
搜索引擎每天的访问量都是海量的,每一秒同时并发的搜索请求都是数以十万计的,在这么多请求面前,如果来一个请求它搜一遍互联网,这肯定是不现实的,不仅速度慢效率低,而且仅仅这类搜索请求就足让整个国际互联网陷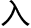 拥堵状态。
拥堵状态。
因为整个互联网的网状结构,使它 备网状互通
备网状互通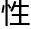 ,所以等爬虫将所有url遍历了,一般来说它就已经将整个国际互联网所有链接全
,所以等爬虫将所有url遍历了,一般来说它就已经将整个国际互联网所有链接全 访问了一遍,这注定是一个比环球旅行更加令人叹为观止的行为。
访问了一遍,这注定是一个比环球旅行更加令人叹为观止的行为。
因为国际互联网中的信息节 都是相互关联的,是网状联系的,每个节上都会有很多个url。所以爬虫的工作模式就是遍历,当它开始工作时,它会以一个信息节为起,然后挨个访寻与这个节相连的所有节,当下一层节还有url链接时,它就不断访问下去,直到将所有url遍历一次才算完。
都是相互关联的,是网状联系的,每个节上都会有很多个url。所以爬虫的工作模式就是遍历,当它开始工作时,它会以一个信息节为起,然后挨个访寻与这个节相连的所有节,当下一层节还有url链接时,它就不断访问下去,直到将所有url遍历一次才算完。
仅仅识别文字还是不够的,它还得能够识别其他格式的数据,比如它得能够识别图案,像是 票相关的各
票相关的各 k线图、
k线图、 状图之类的,爬虫必须能够将其与风景画或者自拍照区别开。
状图之类的,爬虫必须能够将其与风景画或者自拍照区别开。
这样的话,莫回的爬虫就必须在备遍历能力的同时,还得备筛选的能力。
而莫回既然想 这个神1。0,他想要搜集海量数据,那么他要
这个神1。0,他想要搜集海量数据,那么他要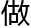 的事情其实和搜索引擎要的事情很像,只不过搜索引擎是所有信息都要搜集,而莫回只需要关注票相关的信息就行了。
的事情其实和搜索引擎要的事情很像,只不过搜索引擎是所有信息都要搜集,而莫回只需要关注票相关的信息就行了。
遍历的能力解释起来很简单,就是你不能走回 路和冤枉路,游历过的url就犯不着再走第二遍了。一条新的url被发现,首先需要判断这条url是否已经走过,其次需要判断这条url被安排在什么次序去走。一个是重复问题,一个是最优化问题,这就需要独特的遍历算法来解决。
路和冤枉路,游历过的url就犯不着再走第二遍了。一条新的url被发现,首先需要判断这条url是否已经走过,其次需要判断这条url被安排在什么次序去走。一个是重复问题,一个是最优化问题,这就需要独特的遍历算法来解决。
而帮助搜索引擎完成找这个动作的就是爬虫。
为了解决这个问题,搜索引擎就有了它特有的工作模式,它先尽可能多的将数据海洋里的信息全找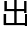 来,然后存储在自己的服务
来,然后存储在自己的服务 群组中,一旦有了搜索请求,它只要在自己的服务里
群组中,一旦有了搜索请求,它只要在自己的服务里 行检索就行了。
行检索就行了。
而筛选功能就是通用爬虫和专用爬虫之间的主要区别,莫回的爬虫需要备一定的识别能力,能够辨别某个url中的内容是否备相关,如果不备那么就 过,如果备就将其中的内容复制回来待用。
过,如果备就将其中的内容复制回来待用。
除了图片,其他的像是视频、音频、各类数据库之类的,爬虫都需要一一辨别来,确定是否属于相关内容。
这里面将会有无数个技术难题需要解决,如果这个工作让莫回一个人来完成,几乎是不可想象的。
这个筛选功能同样需要一大堆的算法来解决,不仅如此,它还需要备自然语言 理能力,就是说它得备对语言文字的理解和解析的能力,它得能够识别哪些文字内容是与票相关的,哪些是无用的。
理能力,就是说它得备对语言文字的理解和解析的能力,它得能够识别哪些文字内容是与票相关的,哪些是无用的。